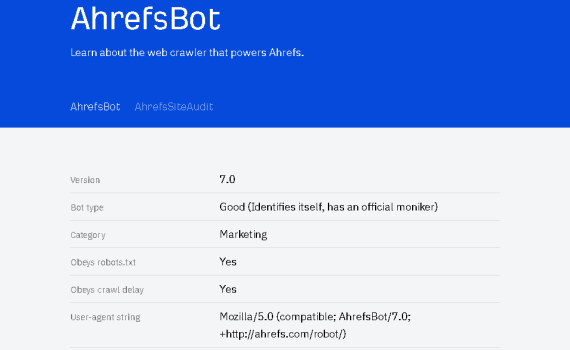
Prevent bad bots from crawling your website Bad bots here, I mean bot like AhrefsBot, which sucked all my VPS resources out, including but not limited to CPU usage up to 30%. So I decided to block it from crawling my website for now. Tried the following two steps, and […]