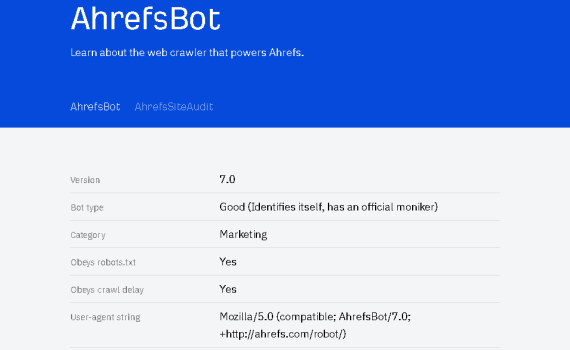

以今年2023年高考语文全国甲卷作文真题为例,来问一下LLM,示范一下怎么写prompt,来利用LLM来指导怎么来写作文
小落同学-3D版本:https://x.rg4.net 20240519 更新: 给小落同学加了Agent支持,后面希望每天要是记得的话就跟她说一下当天的事情,希望的未来是:只要她知道的事情多了,她就会越来越懂我。 注: 本项目为一个奔五的老年程序员在闲暇之余,练习各种新技术之用,暂无其他想法。 由于第1条,本项目的结局(会不会明天就停了)不能得到任何保证,但是如果您也是一个程序员,并且想要本项目或者本项目的代码感兴趣,请直接联系我。let’s ...
Read more »Featured page description text : use the page excerpt or set your own custom text in the customizer screen.
Read more »Featured page description text : use the page excerpt or set your own custom text in the customizer screen.
Read more »