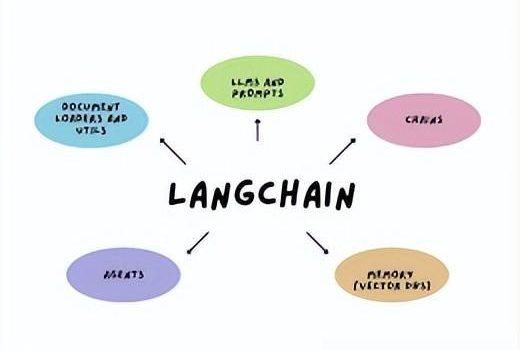
【Good ending】预约会议失败场景下的流程】 小落同学用例:创建一个助手虚拟人,让其可以帮你预约会议。 目标 如题,希望让小落同学虚拟人市场里创建出来的虚拟人可以支持预约会议功能。 创建虚拟人角色 考虑到之前用小落同学的虚拟客服、虚拟女友的角色的prompt偶发会对指令出现干扰,从而导致agent在选择tool时异常,我专门在小落同学的后台新增了一个独立的、助手的角色。进入小落同学的后台后,创建一个虚拟人,名字、性别、人物模型、声音随便选一个,重点是prompt。该角色我给写的prompt是: 启动虚拟人 创建好虚拟人后,可在虚拟人市场那里直接点击启动,跳转到相应的前台页面。 开始预约会议 输入指令 帮我预约一个今天晚上8点的项目会议,邀请Jacky和顾振华参加 请求 工具选择:正确 参数解析:时间和日期全错 将解析日期参数独立出一个tool,再来一遍 在MeetingScheduler这个tool里,我判断了一下日期格式是否正确,如果不对的话,再手动调用QueryDate这个tool去重新解析日期。QueryDate的入参为前面在MeetingScheduler这个tool返回的日期参数:今天晚上8点QueryDate这个 tool的 prompt我写的是: 解析日期请求 第一次解析日期响应1 LLM返回的第一次解析日期的响应如下: 很好,果然笨的可以。那好,既然你这么笨,这道题目哥让你做三遍。 发起第二次QueryDate请求,内容格式跟第一次保持不变。 第二次解析日期响应 LLM返回的第二次解析日期的响应如下: 笨!!但是我还没放弃对你的治疗。发起第三次QueryDate请求,内容格式跟第一次保持不变。 第三次解析日期响应 LLM返回的第三次解析日期的响应如下: 哈哈。虽然你很笨,但是多试几次,你还是有机会把题目做对了的。但是你特么滴能不能按我的要求输出内容?调整QueryDate的prompt,再给你一次机会。 第四次解析日期响应 LLM返回的第四次解析日期的响应如下: 666666 看来还是可以再继续调教调教的。 最终的预约会议结果 Action: MeetingSchedulerAction Input: (‘2024-5-20′, ’20:00’, ‘不循环’, ‘项目会议’, ‘Jacky,顾振华’)Observ[DEBUG][2024-05-20 19:36:31,715][MeetingScheduler.py:80] =====================param=(‘2024-5-20′, ’20:00’, ‘不循环’, ‘项目会议’, ‘Jacky,顾振华’)Observ, type=会议预约:111111111111 […]